| ToC and Pages | Top | Prev, Top, Next |
Splitting
I think it’s time to start splitting up the files. I’ll publish a few more versions, or maybe subsets, as I do this, in case anyone is watching, and for historical purposes (that is, because I want to). But the main thrust will be to try to get a published multi-page version onto GitHub Pages ASAP.
To that end, I think I’ll just split this one big file into one file per section, and name them 01,02, and so on. That should be a simple-enough script.
The first thing is to get Scrivener to put a separator string between our files. It turns out that it knows how to do this. To do so, you need to be using your own output format, not one of the defaults. You begin by popping up a menu on the one to change (I’ve picked Default, since it’s what I’ve been using so far) and you get a copy. You can see Default Copy is already there, since I’ve already created my copy.
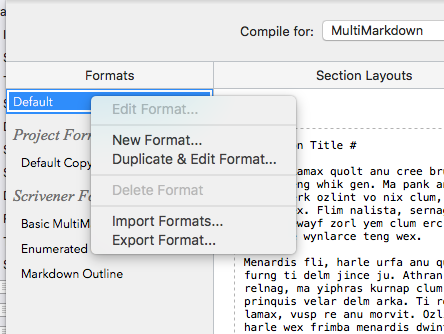
Next step, we’ll edit this and give it a better name, RJ GitHub. And we get the message that it has no assigned layouts. I guess those aren’t copied. I’ll go through that process again, as described above.
Now it turns out, I’m not sure how it happened, this new compile format is creating separators between the sections already, using four dashes, which makes for a horizontal rule in the displayed HTML:
Doubtless because of the layouts I picked, it’s doing it between Sections and not between Sub-Sections, which is just right. This could be good enough to start with, and I think I will.
I’m going to copy the index.md file somewhere safe and see about splitting it.
First attempt, I tried the Bash command csplit. I could get it to do the splitting but it seems not to have a feature to skip the separator line, instead putting it in the next file created. Let’s just bite the bullet and do some Ruby.
We’re in luck, because AmberV (Ioa Petra’ka) of the Scrivener forum has already created an example we can copy. Here’s a link to the article..
Here’s Ioa’s version:
#!/usr/bin/env ruby -wU
require 'tempfile'
SPLIT_MARKER = '>>>> '
FILE_EXTENSION = 'tex'
# Split the input file by markers, writing the contents into temp files. Access temp file with file_chunk['name_of_file.txt']
file_chunks = {}
metadata_block = nil
input = ARGF.readlines
input.join.split(SPLIT_MARKER).each do |chunk|
# Store the first chunk as MMD metadata, to be added to each temp file
unless metadata_block
metadata_block = chunk
next
end
next if chunk.length < 1
filename, *lines = chunk.split("\n")
next if filename[-4..-1] != ".#{FILE_EXTENSION}"
tf = Tempfile.new(filename)
# Add metadata to top of each temp file; unless we're in the reference list
tf.print metadata_block unless filename == "references.#{FILE_EXTENSION}"
tf.print lines.join("\n")
file_chunks[filename] = tf
end
# Pull out the references.txt temp file. We will append it to the bottom of each document that we process. It contains figure and footnote references. Pandoc will ignore any that do not apply to the section, so this can be done blindly.
references = file_chunks.delete("references.#{FILE_EXTENSION}")
file_chunks.each_pair do |filename, tmpfile|
references.rewind
tmpfile.print references.readlines.join("\n")
tmpfile.close
`multimarkdown -t latex -o #{filename} #{tmpfile.path}`
end
I’m going to immediately rip all the fancy stuff out of that, to build up a test script. After more trouble than I’d care to admit, I get this:
#!/usr/bin/env ruby -wU
SPLIT_MARKER = "----\n\n"
filenumber = 0
input = ARGF.read
input.split(SPLIT_MARKER).each do |chunk|
next if chunk.length < 1
title = chunk.split("\n")[0]
if filenumber == 0
filename = "index.md"
else
filename = sprintf("%02d", filenumber) + ".md"
end
filenumber += 1
puts filename + ": " + title
tf = File.new(filename, "w")
tf.print chunk
tf.close
End
That produces this output:
index.md: # Introduction #
01.md: # Style, Scrivener's and Mine #
02.md: # ToC and Pages #
03.md: # Starting the Project #
04.md: # Default Formatting #
05.md: # Styles #
06.md: # Sections #
07.md: # Documents, Sections, Layouts #
08.md: # Regrets, I've had a few #
09.md: # Testing the Compile #
10.md: # Setting up the project #
11.md: # Appendices #
And it produces these files:
Widebody2:ScrivGitPagesScratch ron$ ls
01.md 04.md 07.md 10.md pages.md
02.md 05.md 08.md 11.md splitter.rb
03.md 06.md 09.md index.md
That’s just what I had in mind. Note in the above that since I wanted to produce index.md, I changed the name of the original index.md, containing everything, to pages.md. We’ll need to remember to do that in our compilations, of course.
I’m not particularly proud of this Ruby code, as my Ruby is quite rusty, but in case you’re even more rusty, here’s what it does:
- The script accepts a file name on the command line. I give it
pages.md. It reads in that file as one big string. Then it splits the file on the string—-followed by two newlines, because that’s what happens to be produced by Scrivener. It has double spaced before and after the four dashes. The Rubysplitmethod splits on exactly the characters you give it, not on lines, so my files all had a couple of newlines at the front. That would be harmless to Jekyll, but I know I want the title for table of contents creation. - We loop over each chunk of the file.
- We extract the first line, which will be the Section title.
- If the file number is zero we use the output file name
index.md, otherwise we use the two digits of filenumber,01.md,02.md, and so on. - We print the file name and title, so I can see what’s going on.
- We write the chunk to the file.
All this seems to be working.
Constant readers of my work may be asking themselves, Jeffries, where’s the TDD? Where’s the design? Where are the classes and methods, the clean code?
Those are good questions. My answer, basically, is that this is a bit of a “Spike”, and I don’t generally TDD a Spike unless I’m trying to learn and document something in the system. I’m going to have a moral decision to make as we go forward, whether to set this splitter up with tests, whether to refactor it, or just to let it be a conventional script.
I’m interested to find out what I do, and I hope you are, too. But our main purpose here is to show how to get to GitHub pages, and we’ll focus on that.
I did this in a scratch folder. But I think that if I were to copy index.md and its friends into the root of my ScrivGitPages project and push it, I’d actually have pages to display. Ah … I’d need to copy up all the picture files as well, of course. I think I’ll just do that and we’ll see what happens.
To get as close as possible to the right result, I’ll compile a new version, including these last lines here, into my scratch folder, run the program, move things, and push.
If this works, https://ronjeffries.github.io/scriv-git-pages/ should contain the index file, and I’ll hack a table of contents in by hand for now. If you’re reading this, it worked.
| ToC and Pages | Top | Prev, Top, Next |